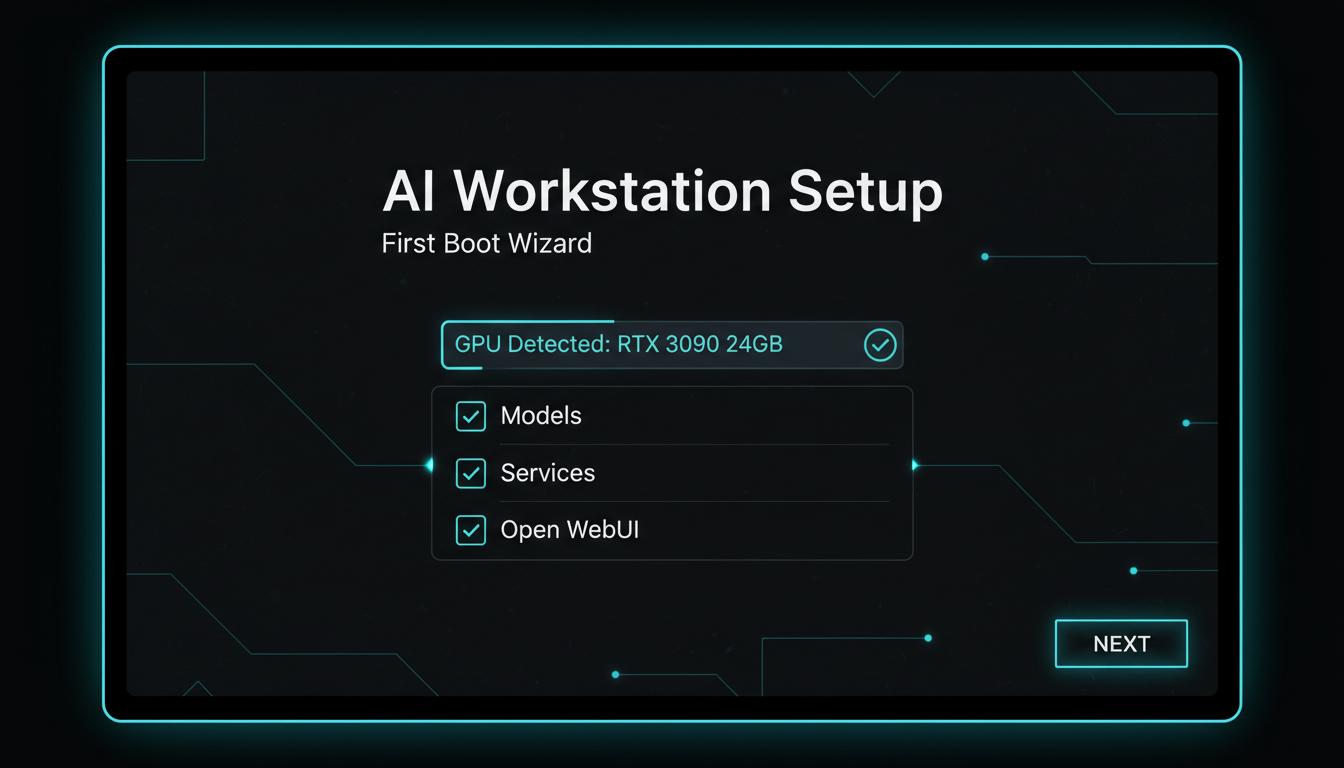
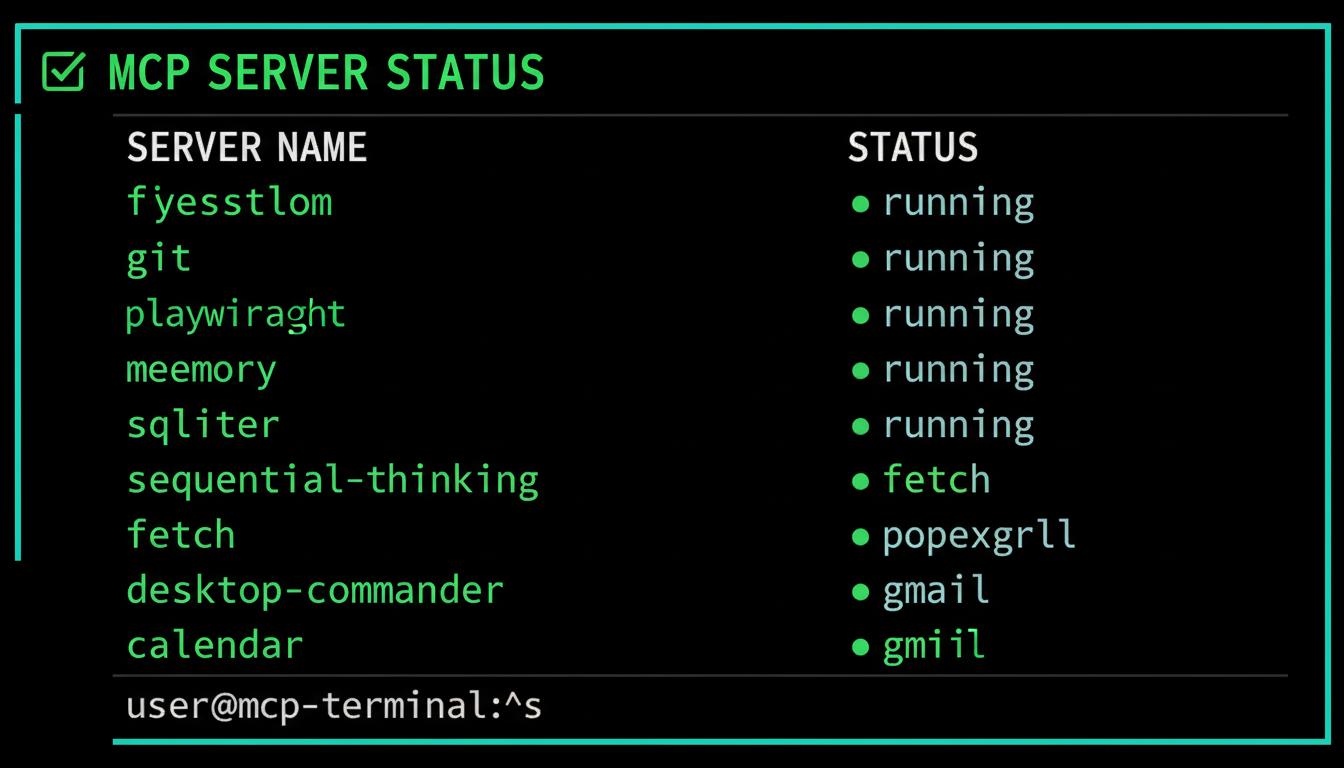
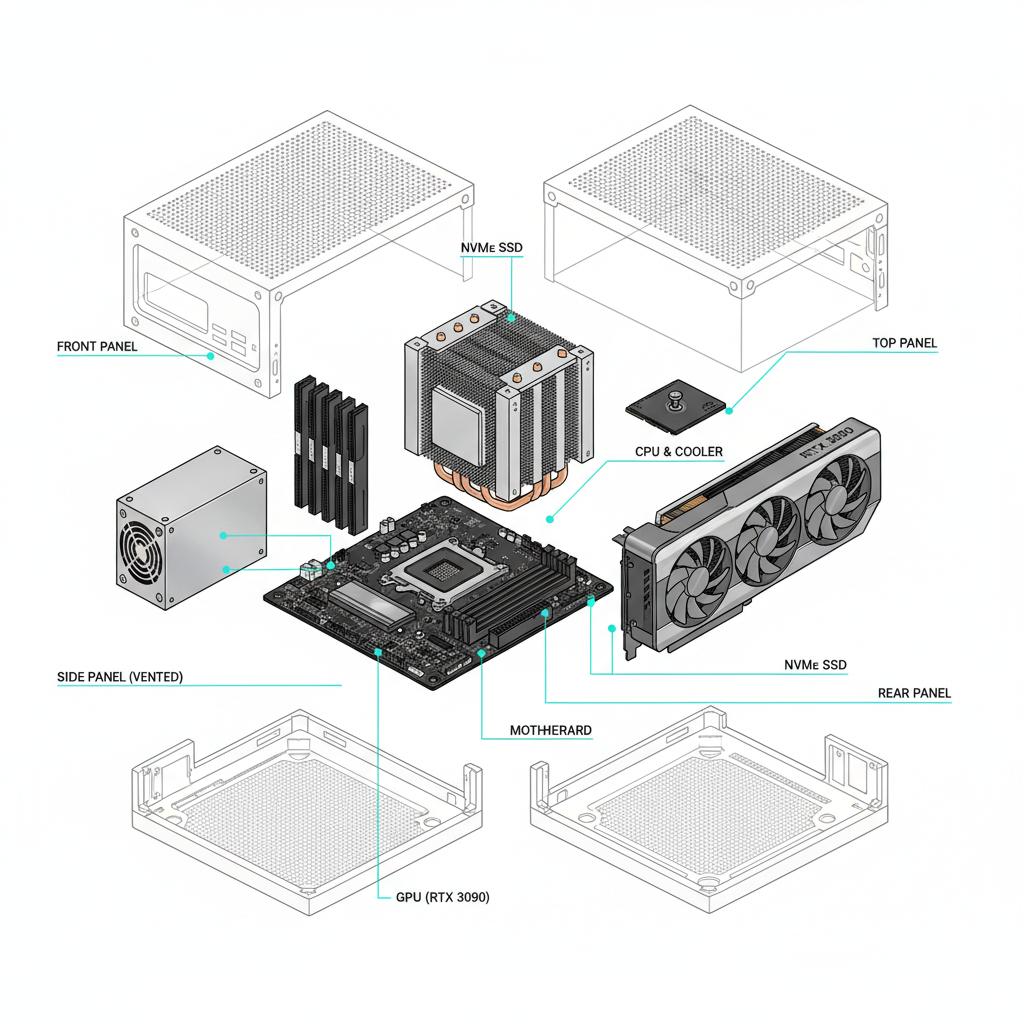
Your AI should work for you.
Not for a server farm 2,000 miles away.
Every query you send to the cloud is a dependency.
On uptime. On pricing. On someone else's privacy policy.
The VAULT eliminates all three.
"The moment your intelligence lives on your hardware,
it answers to you — and only you."
Cloud private intelligence is borrowed intelligence. Rate-limited, retention-tracked,
and one outage away from silence. Private intelligence on your desk is yours — always on,
always private, answering at full speed whether or not the internet exists.
0
+
documented cloud AI outages
since October 2025
Zero
on a machine that never connects